The idea behind
The basic idea behind the project is to have an analytics capable system which has got everything included out of the box.
For those who like to measure things and want to understand better how their user base interacts with their products, we prepared a system which out of the box will give you:
- a fast, scalable solution to ingest user/machine generated events
- a real-time processing pipeline with a collection of common processing tools
- an interactive frontend user interface to explore your data-set in real time.
Contrarily to most analytics systems, Samsara doesn’t aggregate data during the ingestion phase. We leave the aggregation part at query time which gives you more flexibility on choosing which events need to be aggregated and how.
Samsara’s components
Samsara is composed of 4 major parts: the ingestion APIs, the real-time processing pipeline, the live index and query APIs, and the frontend data exploration tool.
There are several other components which are used for internal house keeping.
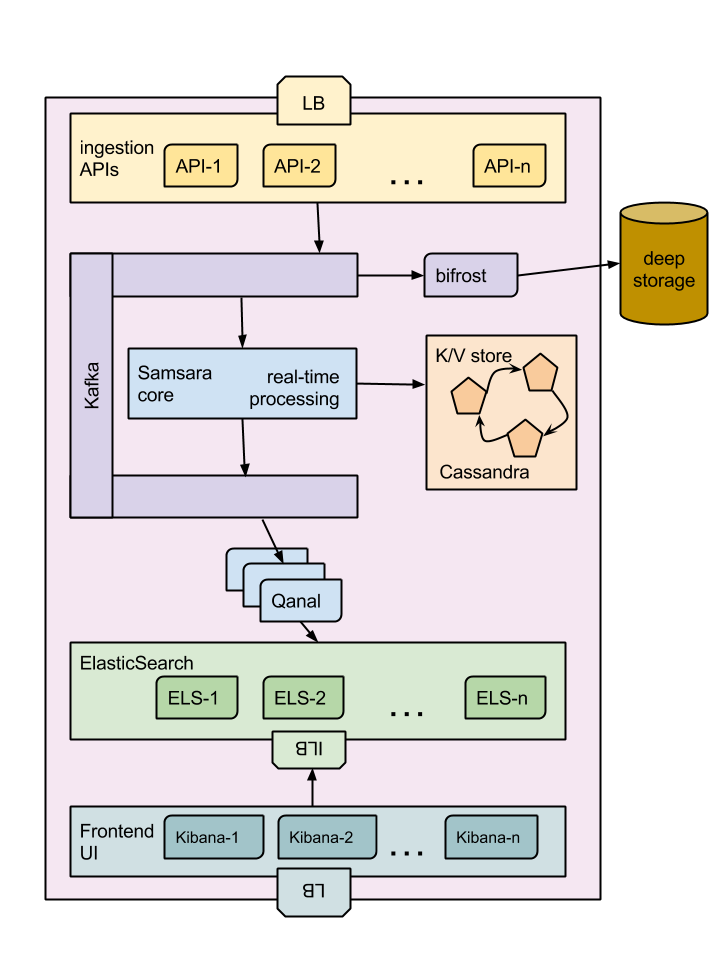
At the top of the stack we find the Ingestion APIs. This tier is an
elastically scalable layer of RESTful web services. They respond to
the client SDKs and accept the payload which is composed by one or
more events. These events are validated and then sent to a high
throughput queueing system such as
Apache Kafka.
Kafka stores the data locally for a certain amount of time, then using eviction policies the data is removed. This interesting property allows the consumer to rewind the topic back in time up to the maximum amount of storage defined in the policy.
For additional durability all the data stored into Kafka is constantly pulled and stored into a deep storage such as HDFS, AWS S3 or Azure Blobs.
Every event sent to Kafka is then processed by Samsara’s CORE. Here events are filtered, enriched and correlated to produce a much richer stream of data. Samsara uses a key-value store, typically an in-memory k/v-store, which is backed by a Kafka stream for durability, but you can optionally spill out to a external database such Cassandra. Samsara CORE uses this in-memory kv-store for transient processing data. The output of Samsara is then sent into another Kafka topic ready to be indexed.
Qanal, our parallel indexer, takes the enriched streams of events and stores them into ElasticSearch.
Once available in the index, the data is immediately queryable by the frontend Kibana which allows to slice-and-dice the data as you need, it computes aggregations and creates powerful real-time dashboards.
Cloud independent vs Cloud Native
Each part of the system can be scaled independently focusing the power in the areas which require it most. The system is build on top of container technology such as Docker, and it can run into Clouds such as AWS and Azure, as well as in premises or your own data-center.
When running in a cloud you are able to choose between a fully cloud independent solution which will leverage only the Virtual machine system of the cloud or you can swap one or more component to use cloud native offering.
The following table shows which native components can be used in a cloud solution:
| Component | Amazon Web Services | Azure Cloud |
|---|---|---|
| Kafka | Amazon Kinesis | EventsHub |
| Cassandra | Amazon DynamoDB | Azure Table |
| Deep storage | Amazon S3 | Azure Blob Storage |
When running in the cloud this is always better to use the load balancers offered, unless you expect your traffic to have long flat lines followed by huge spikes. In that case it is better to run your own load balancers and we recommend HAProxy.